A Data Engineer's Deep Dive into the MCP Toolbox
There is a massive amount of hype suggesting AI is a “magic button” that will instantly replace BI engineers and automate analytics. The reality is far more grounded.
In my experience, these systems don’t fail because the models are weak. They fail because we deploy them against messy production databases without giving them the context that human BI engineers rely on every day.
This article is not about installing an MCP server. It’s about making one actually work in production. I’ll walk through the architectural “last mile” — the specific structural enhancements that turn a text-to-SQL demo into a reliable analytics control plane. The focus is simple:
How do we encode what a good engineer already knows into metadata so the model can reason correctly?
To ground this technically: the tool I’m testing is Google’s open-source MCP Toolbox for Databases. For this implementation, I connected it to a local PostgreSQL instance running via OrbStack. The Toolbox acts as the standardized bridge between the database and the AI client (in my case, Antigravity and VS Code), enabling secure query execution and pooled connections.
There is no shortage of “Getting Started” blogs explaining how to run the npx command. This is
not that. Simply connecting the model to the database is trivial. Making it trustworthy for real
analytics workflows is not.
This post focuses on what can help to move the needle. Because without those, MCP will feel underwhelming.
- Enriched metadata
- Authoritative signals and Data Quality checks
- Add Tribal knowledge
The Magic is in the YAML (and the Metadata)
In its base state, an LLM calling a tool to execute SQL is helpful but not innovative. The real
“magic” happens in the tools.yaml configuration file, which functions as the semantic bridge
between natural language and structured data.
The quality of a model’s output is strictly gated by the quality of its input. To build a high-performing text-to-SQL agent, we need to move beyond raw schema definitions and provide enriched context:
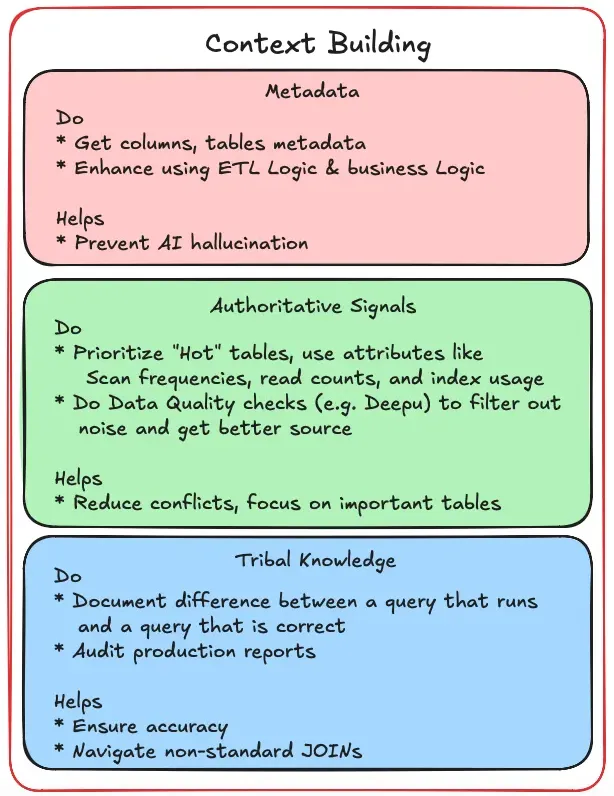
1. Table and Column Metadata
Don’t just provide names; leverage your ETL metadata to provide logic. For example, telling the model that a timestamp is in PST vs. UTC or clarifying if a sales column includes taxes can drastically improve correctness.
Quick Tip: The most efficient workflow I’ve found isn’t manual entry. Instead, feed your existing ETL logic to an LLM agent and task it with generating a source-to-table attribute mapping document. This document should capture the underlying transformations and business logic that usually live only in your code. While you absolutely need Human-in-the-Loop (HITL) review to verify the accuracy of these descriptions, using an LLM for the initial “enrichment” makes building a semantic bridge much faster and more powerful than writing YAML definitions from scratch.
2. Authoritative Signals and the Quality Filter
Databases in the wild are messy, often cluttered with experimental tables or stale backups like
backup_sales_2019 that serve as high-decibel noise for an LLM. By providing metadata on which
tables are actively used by human reporting jobs, you provide an “authoritative signal” that helps
the LLM resolve naming conflicts and avoid “looping” on the wrong data.
However, popularity is a hollow metric if the data itself is malformed. Before labeling a source as authoritative, we must validate for data quality. Large organizations often deploy specialized tools to measure accuracy, while open-source options like Deequ (the engine behind AWS Glue Data Quality) allow you to define specific constraints — such as completeness, uniqueness, or distribution checks — directly on your datasets. By including these quality metrics as part of your metadata, you ensure the AI agent isn’t just querying the “most used” table, but the most accurate one, significantly reducing the “blast radius” of AI-driven analytical errors.
Quick Tip: If you’re starting with a completely unknown database, don’t guess — look at the
information_schemaand internal metadata tables. Look for metrics like table scan frequencies, read counts, and index usage. A table that is frequently read and indexed is a battle-tested source of truth, whereas a table with similar descriptions but zero activity is likely a redundant copy. Prioritizing these “hot” tables allows you to resolve conflicts with high confidence from day one.
3. Embedding Tribal Knowledge: Moving Beyond the Schema
In my experience when you are building data platforms; often contradictory schemas are present. I’ve learned the hard way that a database is rarely a “source of truth.” It is more like a living document filled with historical artifacts, legacy patches, and “gotchas” that never made it into the official documentation.
If you are a fresh engineer tasked with building an MCP server, your biggest mistake would be
trusting the CREATE TABLE statements. The real logic — the tribal knowledge — lives in the SQL
queries currently powering your company’s BI dashboards.
What is Tribal Knowledge, Exactly?
It is the difference between a query that runs and a query that is correct. In a messy production environment, here are some examples:
The “Latest Row” Logic: You might have a sales table where rows are never updated, only
appended. To get the actual sales, you can’t just SELECT *; you need a Common Table Expression
(CTE) to deduplicate and find the latest record by timestamp for every ID.
The Misleading Flag: You see a column named is_active, but your senior architect tells you
it’s been broken since 2019. To find truly active accounts, you actually have to join a separate
dimension_status table and filter by a specific category code.
The “Exclude Test” Filter: Almost every mature database has “test” or “internal” accounts that
skew metrics. Forgetting a WHERE user_email NOT LIKE '%@company.com' is the fastest way to lose
stakeholder trust.
Quick Tip — Reviewing Legacy Reports: Before you start peppering senior architects with questions, review existing reports and SQL scripts written by those who have been “in the trenches” for years. I’ve found that using an LLM as a “query explainer” is a massive force multiplier here. Feed it your most complex, 1,000-line production queries with this prompt:
“Analyze this production query. Identify every filter and join that seems non-standard. What specific attributes are being pulled, and why might this join be necessary instead of using a direct column?”
By reverse-engineering these “special joins,” you identify the logic needed for your
tools.yaml. Now you are ready to talk with team members and ask questions — like verifying if a specific CTE is still the standard logic for handling duplicates — to fill in any gaps the LLM missed.
The divide isn’t between “engineers” and “everyone else.” It’s between the person who tries a tool once and gives up, and the person who iterates long enough to understand its failure modes.
Using an MCP server is a journey of learning limitations. You learn when the model is hallucinating. You learn when your metadata is too thin. You learn when your schema is technically valid but semantically misleading.
A SQL-familiar engineer still has a massive advantage because they can “see through” a generated query and understand the failure point. But the real opportunity isn’t replacement — it’s formalization.
These toolboxes aren’t about replacing engineers. They are about building a production-ready control plane between your orchestration layer and your database — handling connection pooling, security, and observability — while we handle semantics.
Conclusion
Standardizing database context through the MCP Toolbox for Databases allows us to build a robust “semantic bridge” between natural language and structured data. By providing enriched metadata like authoritative signals and tribal logic, we move away from the high-friction cycle of context-switching between the IDE and the DB. This isn’t about replacing the data professional; it is about providing the AI with the grounding it needs to handle the boilerplate while you remain the manager of the code it generates.
The better we encode our tribal knowledge, the more powerful these systems become.
The Roadmap: What’s Next
Moving forward, I am shifting from exploratory demos with an experimental phase focused on the following:
Evaluation & Accuracy: I will be implementing evaluation frameworks to measure faithfulness (ensuring the model stays grounded in the source) and helpfulness (comprehensive, relevant responses).
Schema Stress-Testing: I’ll be experimenting with diverse schema types — from organized star-schemas in a retail sandbox to messy, real-world production instances — to see how metadata density impacts query success.