The End of Cheap Tokens

The “Qwen” Moment: Why I Stopped Chasing the Frontier LLM Models
As a developer using Antigravity and AWS Kiro daily, I used to select the best model for my task. I assumed the brain behind my coding agent was coming from the most latest (and the most expensive) model available. At the end of task, I had my “Aha!” moment: I thought Gemini Pro was doing the heavy lifting, but it was actually an older version of Qwen model was running in the background.
The most shocking part wasn’t just the name of the model — it was that I didn’t notice the difference.
- Near Zero Coding Degradation: The quality of the generated code remained high. It was solving logical problems was identical to my experience with flagship models.
- Tool & Reasoning Parity: The way the IDE used internal tools and followed multi-step reasoning traces remained perfectly consistent.
My mind shifted instantly. I realized that for 80% of my research and debugging, I didn’t need the “greatest” model. I just needed one that was available and cheap.
Think of it like calling an Uber. If you need to get from Point A to Point B, do you really care if the SUV is a Ford or a Chevy? As long as the ride is safe and on time, the brand of the engine is irrelevant. This is the commoditization of intelligence.
Aggregators: The New “Travel Agents” of Code
This realization is why services like Perplexity are winning. They nail the “Agent” configuration, using whatever tool or model is best for the specific task at hand.
In the future, we won’t be selecting models; we’ll be using “Travel Agents” (aggregators) who decide when to opt for a lightweight model like Gemini Flash or GPT-4o Mini to save us 95% on costs without sacrificing the “ride” quality.
In this new world, the power isn’t in only the raw model; it’s in the orchestration.
Buying an “Option” on Intelligence
As AI becomes a utility, the way we pay for it is changing. Right now, we’re in the “honeymoon phase” of flat-rate tokens. But just as American Airlines pioneered dynamic pricing in the 1970s and AWS introduced Spot Instances in 2009, AI compute is becoming a perishable resource.
Buying an API call is becoming like buying a concert or airline ticket. You aren’t just paying for data; you are buying an option — a reserved spot in a GPU cluster that guarantees your code will run even when the rest of the world is hitting the servers.
We are moving past the era of simple, unpredictable pay-per-call. Today, giants like Microsoft and OpenAI are selling Provisioned Throughput (PTU) which is the AI equivalent of an AWS Reserved Instance. You aren’t just buying a single response, you are securing dedicated compute capacity measured in tokens per minute. This is like buying an option with “anti-throttling” insurance.
While the rest of the world is fighting for bandwidth on crowded “public” API endpoints, your reserved spot in the GPU cluster.
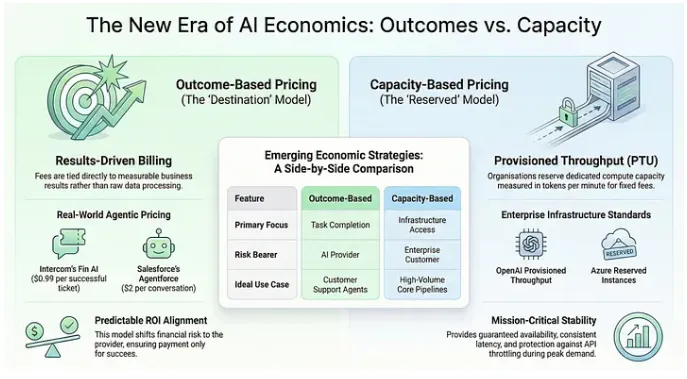
Tokens vs. Outcomes: A New Design Decision
The most disruptive shift will be the move to Outcome-Based Pricing. As an engineer, I see this as a core design decision.
- The Token Model: I’ll keep paying per token for the low-stakes stuff — simple automation scripts, code reviews, or conversational agents. It’s cheap and efficient for “fuel-based” tasks.
- The Outcome Model: But when a Spark cluster fails or a CI/CD pipeline goes dark for an active business website, I’ll gladly pay a $1.00 guaranteed result fee. It shifts the risk from the developer to the provider, ensuring that we only pay when the thing actually works.
In high-stakes industry environments, paying for the “destination” (a resolved ticket) instead of the “fuel” (tokens) is simply more honest.
Consider these operational scenarios:
The Customer Support Agent. Instead of paying for every token a chatbot “thinks” about, companies like Intercom (Fin AI) now charge $0.99 per successful ticket resolution. If the AI fails to solve the problem and must escalate it to a human, you pay nothing.
The Conversational Sales Bot. Salesforce’s Agentforce has introduced a model charging $2 per conversation handled. You aren’t paying for the “fuel” (tokens) — you are paying for the “destination” (the engagement).
Conclusion: Mastering the AI Utility
The AI industry is finally maturing, following the same path as airlines in the 1970s and cloud compute in 2009. We are moving from “experimental novelty” to “deep industrialization”. While flat-rate subscriptions were the “on-ramp” for the masses, the future belongs to those who can navigate a complex matrix of Provisioned Throughput and Outcome-Based models.
As we hit performance parity among top-tier models, we must stop “model chasing” and start focusing on Utility Management. Our future technical designs will be defined by a new set of questions: Do we buy Reserved Capacity to ensure our critical pipelines never throttle? Or do we opt for Outcome-Based pricing to align our costs with guaranteed results? The goal remains the same: getting from Point A to Point B as efficiently as possible.